Why are you here?
Recently, In every industry, everyone is talking about machine learning. In last few years, ML popularity increases exponentially.
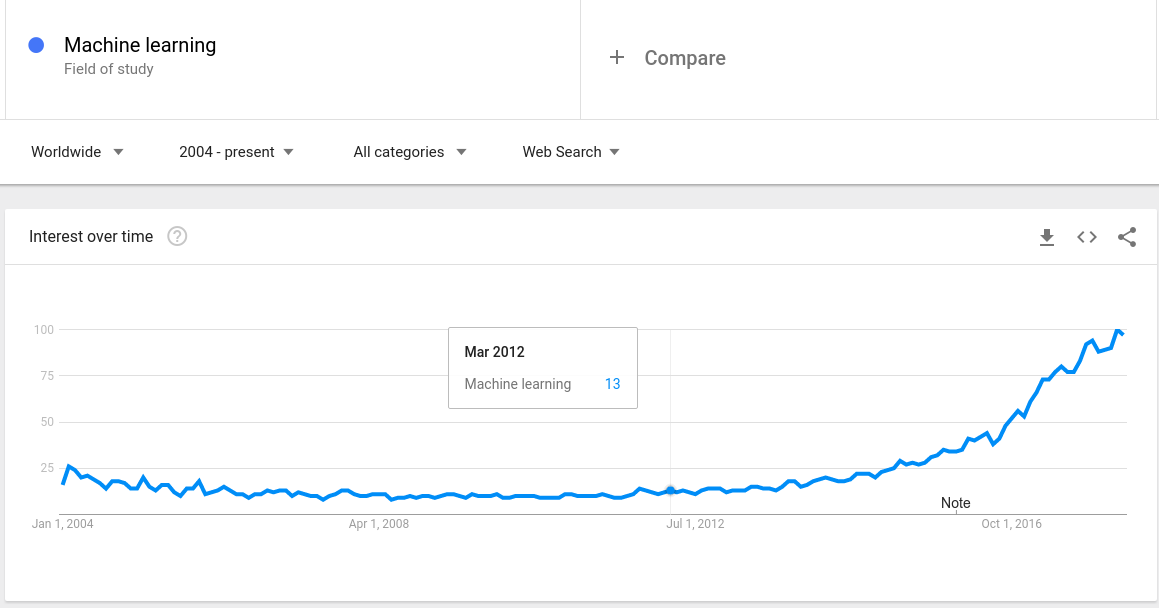 A graph shows the popularity of machine learning topic from 2004. As shown from 2012 to 2016 it increases by 400%. Every day hundreds of researcher publishing papers about how ML can be used in different domains. ML has a large number of use cases from simple sales prediction to complex medical image processing.
A graph shows the popularity of machine learning topic from 2004. As shown from 2012 to 2016 it increases by 400%. Every day hundreds of researcher publishing papers about how ML can be used in different domains. ML has a large number of use cases from simple sales prediction to complex medical image processing.
1 year ago I started exploring ML and I found it is quite interesting. But learning ML concept is quite hard for beginners because of there is nothing right or wrong in ML. You can apply the same solution to every problem and it will give you some result. Difficulty increase when you need to get state of art result for a particular problem. You will find so many tutorials for machine learning algorithms but an understanding of the underlying mechanism is hard. The same problem happens to me also, When I work on the problem I can copy and paste the code from a different similar problem and get a good result. But when I need to improve this model I can only do one thing “Try and Try…”. And found this will not work 90% of the time. So I decided to revise all my understanding of ML deeply and document it. This post and following posts will have only one focus and That is “Deep understanding of the concept”. I will try to research and document methodology, concept, use case and result. Hope it Helps!!
Introduction
Consider One architecture model which takes lots of data as input. With this data and some algorithms model with learn relationships and patterns within data. After this learning phase now if we ask this model some question by giving data it will try to match given data to relationships and pattern found during learning and gives an answer.
Machine Learning is a field which tries to take above model and solve a different problem.With different problem Model + Data + Learning will change. The goal of machine learning is to get best model which can solve a problem efficiently and accurately.
You can solve many problems with one model and different data. with different data, knowledge gain by learning will be different and hence output will be different for each problem. to understand this take an example of Bob, Bob doesn’t know how to cook pizza so Bob goes to recipe website and read about how to make pizza. After reading Bob acquired knowledge of making pizza and now Bob can make delicious pizza. After that bob decides to make pasta and again goes to a website and learn about it.
Relate this example to machine learning concept. Bob is our model. make pizza is one problem. By reading a recipe which is our Data, Bob learns to make pizza. and an outcome is Bob can now make pizza. now change problem to make pasta and as we noticed only data is changed and with this data, acquired knowledge is different and result also changed but model(Bob) is still same. In my opinion flexibility like this is the main reason for ML popularity.
Classification of machine learning problem
We can classify Machine learning problem based on output produce by model and what input model required. Based on this we can classify problem in two categories.
- Supervised learning
- Unsupervised learning
1. Supervised learning
In Supervised learning we know which output we are looking for based on input data. In other words, there is a relationship between input and output. In terms of math, $ Y = F(x) $ is a simple equation for Supervised learning. Based on a type of $ F(x) $ we can divide Supervised learning problem into 2 category
- Regression (where $ Y $ is a continuous function) :
- In regression output of a model is continuous function means if we plot all values of Y we will get an unbroken line on a graph.
- Eg. problem “Predict temperature of a city” comes under regression because of we plot all possible value of output, It will be a continuous line
- Classification (where $ Y $ discrete function) :
- In classification, we have only a few values of Y for each input. we can treat Y as a category which we are trying to map with each input
- Eg. predict the type of car
2. Unsupervised learning
In Unsupervised learning, we do not have any idea about how our result looks like. We feed data and expect a model to give us relationships in data. Clustering is Unsupervised learning technique which used to find relationships and make cluster of that
Conclusion
ML is fascinating subject with endless possibility. In this post, we covered basic terminology like a model type of ML problems. In Next post, I will go deep into model and math behind it. Add a comment below if you have any doubt.